


By T. Mertzimekis
Today, I am dealing with Deep Learning, a subfield of machine learning (ML), which has gained tremendous popularity in recent years due to its ability to tackle complex problems and achieve state-of-the-art results. At the core of deep learning lies (artificial) neural networks, which are instrumental in processing and understanding vast amounts of data. In this blog article, I am exploring the essential steps involved in applying neural networks for deep learning, providing a comprehensive roadmap for building successful deep learning models.
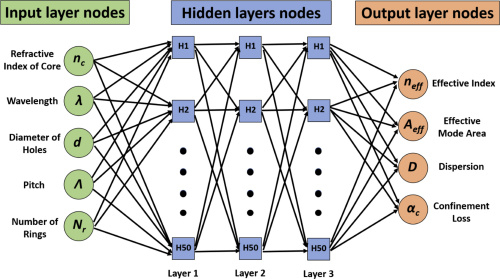
Artificial Neural Networks
Neural networks, also known as artificial neural networks (ANNs), are a class of mathematical models designed to mimic the functioning of the human brain. They consist of interconnected nodes called artificial neurons or simply "neurons." These neurons are organized into layers, with each layer responsible for performing specific computations. The connections between neurons are represented by weights, which determine the strength and significance of the information flowing through the network.
Data Collection and Preprocessing
The first crucial step in any deep learning project, including the application of ANN, is data collection. Depending on the task at hand, the relevant data needs to be gathered and organized. This may involve acquiring labeled data for supervised learning tasks or curating large datasets for unsupervised or semi-supervised learning.
Once the data is collected, preprocessing is necessary to ensure its quality and compatibility with the neural network model. Preprocessing steps may include data cleaning, normalization, handling missing values, and feature scaling. Additionally, data augmentation techniques can be employed to increase the diversity and size of the training data, which helps the neural network generalize better.
Architecture Design
The architecture of a neural network defines its structure, determining how the network will process and learn from the input data. Architectural design choices have a significant impact on the model's performance and computational requirements. Various types of neural networks, such as feedforward neural networks (FFNN), convolutional neural networks (CNNs), recurrent neural networks (RNNs), and transformers, have specific architectures suited for different data types and tasks.
Selecting the appropriate architecture involves considering factors like the input data dimensions, the complexity of the problem, the presence of spatial or temporal dependencies, and available computational resources (that is always an essential requirement for ML methods). Experimentation with different architectures, such as varying the number of layers, layer sizes, and activation functions, is often required to find the optimal design for the given task.
Model Training
Training a neural network involves optimizing its parameters to minimize a predefined loss function. The training process is typically iterative and consists of the following steps:
a. Initialization: Initialize the network's weights and biases with suitable values. Random initialization is commonly used, ensuring that the network starts with different configurations and explores a diverse parameter space.
b. Forward Propagation: Pass the input data through the network, layer by layer, calculating the activations of each neuron. This process propagates the input data forward, producing an output prediction.
c. Loss Calculation: Compare the network's predicted output with the ground truth labels using a loss function. The choice of the loss function depends on the nature of the task, such as mean squared error for regression or cross-entropy loss for classification.
d. Backward Propagation (or Backpropagation): Use the calculated loss to update the network's weights and biases, aiming to minimize the loss. This step involves calculating the gradients of the loss with respect to the network's parameters and adjusting them using optimization algorithms like gradient descent or its variants.
e. Iteration: Repeat the forward and backward propagation steps for multiple epochs, where each epoch consists of a complete pass through the training dataset. This iterative process allows the network to adjust its parameters and improve its performance over time.
Hyperparameter Tuning
Deep learning models have various hyperparameters that require tuning to achieve optimal performance. Hyperparameters include learning rate, batch size, regularization techniques, optimization algorithms, and activation functions. Finding the right combination of hyperparameters is crucial for obtaining accurate and robust models.
Hyperparameter tuning can be performed using techniques such as grid search, random search, or more advanced methods like Bayesian optimization or genetic algorithms. The process involves training and evaluating the model with different hyperparameter configurations to identify the best-performing settings.
Model Evaluation and Validation
Once the model is trained, it is essential to evaluate its performance on unseen data to assess its generalization capabilities. This evaluation helps determine if the model has learned meaningful representations or if adjustments need to be made.
Cross-validation and holdout validation are commonly used techniques to estimate the model's performance. Additionally, various evaluation metrics, such as accuracy, precision, recall, F1-score, or area under the receiver operating characteristic curve (AUC-ROC), can be utilized depending on the specific task and requirements.
Deployment and Monitoring
After successful training and validation, the trained neural network model can be deployed for inference on new, unseen data. The deployment can take various forms, such as integration into web applications, mobile apps, or embedded systems, depending on the application's requirements.
It is crucial to monitor the model's performance and retrain it periodically on fresh data to maintain its accuracy and adaptability to evolving scenarios. Monitoring can involve tracking metrics, detecting model drift, and implementing techniques like transfer learning to update the model with new data.
Advantages of Neural Networks in Deep Learning
Ability to Learn Complex Patterns: One of the key advantages of neural networks is their ability to learn and identify intricate patterns in data. With multiple layers and millions of interconnected neurons, deep neural networks can automatically extract hierarchical representations from raw input data. This hierarchical feature extraction allows them to capture complex relationships and nuances that may be difficult for other machine learning algorithms to discern.
Exceptional Performance on Large-Scale Data: Neural networks thrive in scenarios where large amounts of labeled data are available. By leveraging their capacity to learn from massive datasets, deep learning models can achieve impressive performance on tasks such as image classification, speech recognition, and natural language understanding. The availability of vast amounts of data has been crucial in training deep neural networks to outperform traditional algorithms in various domains.
Feature Extraction and Representation Learning: Deep neural networks possess the capability to automatically learn relevant features from raw data. Unlike handcrafted feature engineering, where domain experts manually design features, neural networks learn hierarchical representations that capture both low-level and high-level features. This feature extraction and representation learning enable deep learning models to effectively generalize across different datasets and tasks.
Adaptability to Diverse Data Types: Neural networks can handle diverse types of data, including images, audio, text, and time-series data. Convolutional Neural Networks (CNNs) excel at image analysis, Recurrent Neural Networks (RNNs) excel at sequential data processing, and Transformers excel at natural language processing tasks. This versatility makes neural networks suitable for a wide range of applications, making them a go-to choice in many deep learning projects.
Drawbacks of Neural Networks in Deep Learning
Not all is roses. ANN may have some drawbacks, too.
Large Computational Requirements: Training deep neural networks often requires substantial computational resources, including powerful GPUs or specialized hardware accelerators. The massive number of parameters and complex architectures of deep networks contribute to their computational demands. Consequently, training large-scale models can be time-consuming and costly, limiting their accessibility to researchers and organizations with sufficient resources.
Data Dependency and Overfitting: Neural networks are highly data-dependent and require substantial labeled data for training. In scenarios where labeled data is scarce or costly to obtain, the performance of deep learning models may suffer. Moreover, neural networks are prone to overfitting, a phenomenon in which the model becomes overly specialized to the training data, leading to poor generalization on unseen data. Overfitting can occur when the network is too complex relative to the available training data.
Lack of Interpretability: Another limitation of neural networks is their lack of interpretability. Due to their highly complex and non-linear nature, it is challenging to understand the internal workings of deep learning models. While they can produce accurate predictions, the reasoning behind those predictions is often opaque.
A final word
Applying neural networks for deep learning involves a series of essential steps, from data collection and preprocessing to architecture design, model training, hyperparameter tuning, evaluation, and deployment. Each step requires careful consideration and experimentation to build accurate and robust models. Understanding these steps and their significance is crucial for effectively harnessing the power of neural networks and unlocking the full potential of deep learning in various domains.