


By T.J. Mertzimekis
With the present blog post I conclude the series of posts dedicated to machine learning methods that are commonly used for various applications. Despite not exhaustive and rather at introductory level, this series can be used as a quick reference for the interested reader. A simple search in the internet can return millions of results about machine learning and references can be tracked down for further research and development. This post can be considered as a continuation to the previous one on Natural Language Processing (NLP). Word Embedding focuses on textual content and how it can be processed to examine word semantics and correlations.
1. Introduction to Word Embedding
Word embedding is a revolutionary technique in the field of Natural Language Processing (NLP) and Machine Learning (ML). At its core, word embedding is a way to represent words as dense vectors of real numbers. This representation captures semantic relationships between words, allowing machines to understand language in a more nuanced way. Unlike traditional methods that treat words as discrete symbols, word embedding transforms words into a continuous vector space. This transformation enables algorithms to perform mathematical operations on words, revealing fascinating linguistic patterns and relationships.
2. The Importance of Word Embedding in Natural Language Processing
Word embedding has become a cornerstone of modern NLP for several reasons:
- Semantic Understanding: It captures semantic similarities between words, allowing models to understand that words like "king" and "queen" or "cat" and "kitten" are related.
- Dimensionality Reduction: It represents words in a dense, low-dimensional space, making it computationally efficient to process large vocabularies.
- Improved Performance: Many NLP tasks, from machine translation to sentiment analysis, have seen significant improvements by using word embeddings.
- Transfer Learning: Pre-trained word embeddings can be used across different NLP tasks, allowing models to leverage knowledge gained from vast amounts of text data.
3. How Word Embedding Works
At a high level, word embedding works by analyzing the context in which words appear in large text corpora. The fundamental idea is that words that frequently appear in similar contexts are likely to have related meanings.
The process typically involves the following steps:
- Corpus Analysis: A large body of text is analyzed to understand word co-occurrences.
- Vector Assignment: Each word is assigned a vector in a multi-dimensional space.
- Training: The vectors are adjusted based on the word's context in the corpus, optimizing for predictive accuracy.
- Fine-tuning: The embeddings can be further refined for specific tasks or domains.
4. Popular Word Embedding Techniques
Several methods have been developed for creating word embeddings:
- Word2Vec: Developed by Google in 2013, Word2Vec uses shallow neural networks to learn word associations from a large corpus of text.
- GloVe (Global Vectors): Created by Stanford researchers, GloVe combines global matrix factorization and local context window methods.
- FastText: Developed by Facebook, FastText extends Word2Vec by using subword information, allowing it to generate embeddings for out-of-vocabulary words.
- BERT (Bidirectional Encoder Representations from Transformers): While not a traditional word embedding technique, BERT produces contextualized word representations that have shown state-of-the-art performance on many NLP tasks.
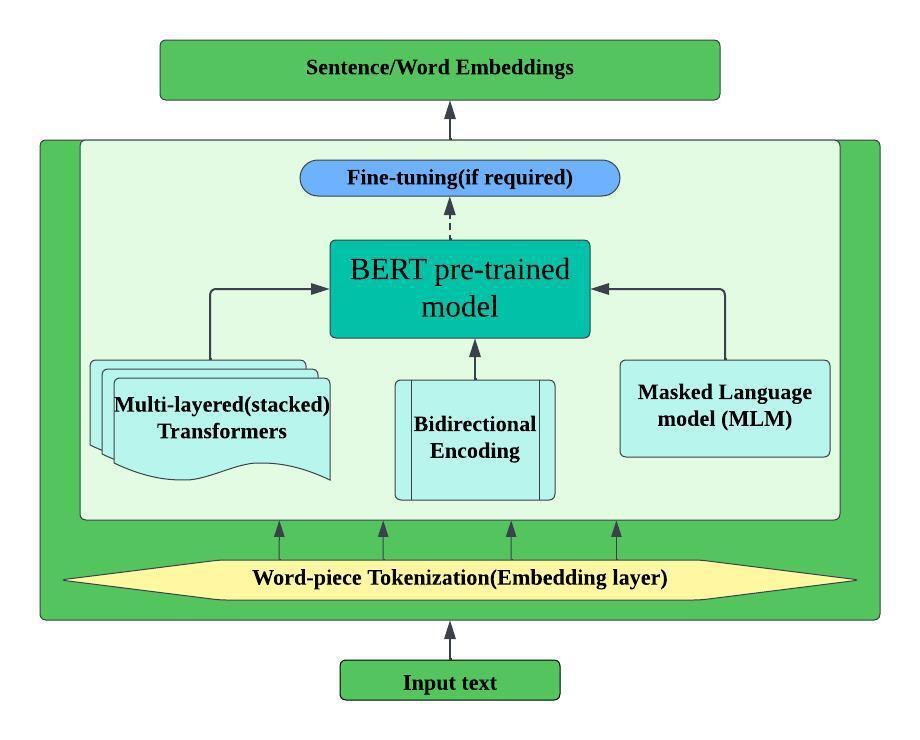
Figure 1: BERT Block Architecture
5. Applications of Word Embedding in Machine Learning
Word embeddings have found applications in numerous ML and NLP tasks:
- Text Classification: Sentiment analysis, spam detection, topic categorization.
- Named Entity Recognition: Identifying and classifying named entities in text.
- Machine Translation: Improving the quality of language translation systems.
- Information Retrieval: Enhancing search engines and recommendation systems.
- Question Answering: Powering chatbots and virtual assistants.
6. Challenges and Limitations
Despite their power, word embeddings face several challenges:
- Handling Polysemy: Words with multiple meanings can be challenging to represent accurately.
- Bias in Embeddings: Embeddings can reflect and amplify societal biases present in the training data.
- Out-of-Vocabulary Words: Some techniques struggle with words not seen during training.
- Context-Dependent Meanings: Traditional embeddings assign a single vector to each word, regardless of context.
7. Future Directions
The field of word embedding continues to evolve:
1. Contextual Embeddings: Models like BERT and GPT are pushing towards context-dependent word representations.
2. Multilingual Embeddings: Research is ongoing to create embeddings that work across multiple languages.
3. Debiasing Techniques: Methods are being developed to reduce bias in word embeddings.
4. Domain-Specific Embeddings: Creating embeddings tailored for specific industries or fields.
Word embedding has revolutionized how machines understand and process human language. As research continues, we can expect even more powerful and nuanced ways of representing the complexity of language in the world of machine learning.