


By T.J. Mertzimekis
1. Introduction
This is the next chapter in the series of reviewing well established machine learning methods. It has already been mentioned in previous posts that Machine learning (in short, ML) has revolutionized various fields, from image recognition to natural language processing (a dedicated post on this will follow). Among its various techniques, reinforcement learning (RL) stands out for its potential to solve complex decision-making problems by learning through interaction with the environment. In this blog post, we'll explore the fundamentals of reinforcement learning, its applications, and some representative examples that illustrate its capabilities.
2. What is reinforcement learning?
Reinforcement learning (RL) is a type of machine learning where an agent learns to make decisions by performing actions in an environment to maximize cumulative rewards. Unlike supervised learning, where the model is trained on a labeled dataset, RL involves learning from the consequences of actions, which makes it particularly suitable for problems where data is not readily available or where the optimal decision-making process is complex. In RL, the agent interacts with the environment in a loop:
State (S): The agent observes the current state of the environment.
Action (A): Based on this observation, the agent chooses an action.
Reward (R): The environment responds by providing a reward signal.
Next State (S'): The environment transitions to a new state.
The agent's goal is to learn a policy (a mapping from states to actions) that maximizes the total reward over time.
3. Key Concepts in Reinforcement Learning
To understand RL more deeply, let's break down its key components:
Policy (π): The policy is a strategy used by the agent to determine the next action based on the current state. It can be deterministic (π(s) = a) or stochastic (π(a|s) = P(a|s)).
Value Function (V): This function estimates the expected reward that can be obtained from a state or a state-action pair. The state value function V(s) predicts the expected return starting from state s and following the policy π.
Q-Function (Q): Also known as the action-value function, Q(s,a) provides the expected return for taking action a in state s and thereafter following the policy π.
Reward (R): The immediate feedback received after taking an action in a particular state. It guides the learning process by encouraging the agent to achieve higher rewards.
Exploration vs. Exploitation: A fundamental dilemma in RL. Exploration involves trying new actions to discover their effects, while exploitation involves choosing the best-known action to maximize the reward.
4. Mathematical Formulation
Reinforcement learning problems are often formulated as Markov Decision Processes (MDPs), which provide a mathematical framework for modeling decision-making in situations where outcomes are partly random and partly under the control of the decision-maker. An MDP is defined by:- A set of states S
- A set of actions A
- A state transition probability P(s'∣s,a)
- A reward function R(s,a)
- A discount factor γ∈[0,1], which models the importance of future rewards. The goal in an MDP is to find an optimal policy
π∗ that maximizes the expected return:
[math] V^\pi(s)=\mathbb{E}\left[\sum_{t=0}^{\infty}\gamma^t R(s_t,a_t)|s_0=s,\pi\right] [/math]
where [math] s_t [/math] is the state at time t and [math]a_t[/math] is the action taken at time t under policy π.
5. Reinforcement Learning Algorithms
There are several RL algorithms, each with unique approaches to learning optimal policies. Here, we briefly discuss a few of the most important ones:
a. Q-Learning: Q-Learning is an off-policy algorithm that aims to learn the optimal Q-function, Q*(s,a). The update rule for Q-Learning is:
[math] Q(s_t,a_t)\leftarrow Q(s_t,a_t)+a\left[R(s_t,a_t)+\gamma\max_aQ(s_{t+1},a_t)-Q(s_t,a_t)\right] [/math]
where [math]a[/math] is the learning rate. The policy is derived by selecting the action with the highest Q-value in each state. The policy is derived by selecting the action with the highest Q-value in each state.
b. Deep Q-Networks (DQN): Deep Q-Networks extend Q-Learning by approximating the Q-function with a neural network. This allows RL to scale to environments with large or continuous state spaces. The key innovation in DQN is the use of experience replay and target networks to stabilize training.
c. Policy Gradient Methods: Instead of learning a value function, policy gradient methods directly learn the policy function. The objective is to maximize the expected reward by adjusting the policy parameters θ in the direction of the gradient:
[math] \nabla_\theta J(\theta)=\mathbb{E}\left[\nabla_\theta\log\pi_\theta(a|s)Q^{\pi_\theta}(s,a)\right] [/math]
These methods are particularly useful in environments with continuous action spaces.
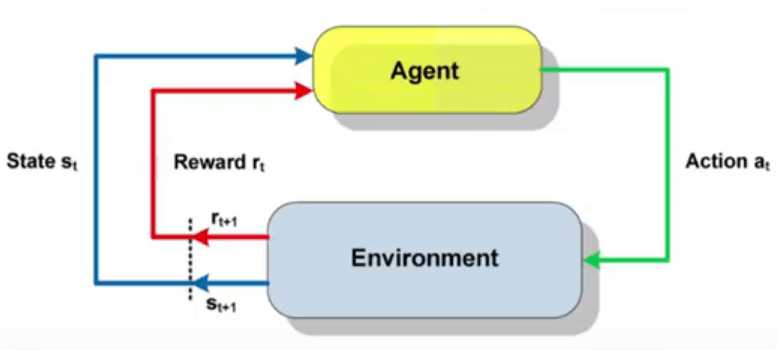
Figure 1. The reinforcement learning loop: the agent interacts with the environment by observing the state, taking actions, and receiving rewards, which guide the policy update process.
6. Representative Examples of Reinforcement Learning
a. Game Playing: AlphaGo. One of the most famous applications of RL is Google's AlphaGo, which used deep reinforcement learning to defeat world champions in the game of Go. AlphaGo combined supervised learning on expert games with reinforcement learning from self-play to train its neural networks. It utilized a variant of the policy gradient method and Monte Carlo Tree Search (MCTS) to evaluate the possible future states of the board, making strategic decisions that led to its success.
b. Finance: Portfolio Optimization. In finance, RL has been applied to portfolio management, where the goal is to dynamically adjust the portfolio's asset allocation to maximize returns while managing risk. An RL agent can be trained to optimize the asset distribution by interacting with the market, learning from historical data, and adjusting the portfolio based on current market conditions. Techniques like Q-Learning and Policy Gradient have been used to tackle this problem.
7. Challenges and Future Directions **
Despite its successes, reinforcement learning faces several challenges:
- Sample Efficiency: RL algorithms often require a large number of interactions with the environment to learn effectively. This is particularly problematic in real-world applications where such interactions are costly.
-Exploration: Balancing exploration and exploitation is challenging, especially in environments with sparse rewards.
- Generalization: RL models can struggle to generalize from the training environment to new, unseen environments.
Future research is focusing on improving sample efficiency through model-based RL, developing better exploration strategies, and enhancing the robustness and generalization of RL algorithms.
8. Closing remarks
Reinforcement learning is a powerful technique within the machine learning domain, with the potential to solve complex decision-making problems across various fields, including games, robotics, and finance. By interacting with the environment and learning from the consequences of actions, RL agents can develop sophisticated strategies that are difficult to achieve through traditional programming methods.